Von Büchern zu Topics: So gelingt bessere User Experience
1) Technologiewechsel: HTML statt PDF
HTML als neuer Ausgabekanal
Wenn wir uns die aktuellen Vorhaben in der Technischen Dokumentation anschauen, dann wird ein Thema weiterhin nur sehr selten betrachtet: Der Wechsel von der Buchorientierung (Papier- oder PDF-Dokumente) hin zur digitalen Benutzerassistenz auf Basis von Topics (HTML-Seiten).
Ein Teil dieses Paradigmenwechsels ist in vielen Firmen jedoch en vogue: Die Ergänzung der PDF-Ausgabe um eine HTML-Ausgabe. Viele Firmen möchten die HTML-Ausgabe als rein technisches Problem begreifen und dadurch die Aufwände möglichst gering halten.
Technisch ist der zusätzliche Ausgabekanal "HTML" als einmaliger Aufwand für Systemhersteller und Systemarchitekten keine wirkliche Herausforderung. Wer Online-Hilfen für Software erstellt, weiß schon seit mehr als 20 Jahren, welche technischen Besonderheiten HTML-Ausgaben gegenüber PDF-Dokumenten haben.
Wenn wir die HTML-Ausgabe als reine Konvertierung der bisherigen Dokumente verstehen – welchen zusätzlichen Nutzen haben die Anwender dann?
Dokumentationszweck und die Eignung von Papier und PDF
Technische Dokumentation soll bekanntlich einen bestimmten Zweck erfüllen: Eine Zielgruppe zur richtigen Zeit mit den erforderlichen Produkt- und Handlungsinformationen schnellstmöglich zum Handeln befähigen. Lernkonzepte, Lehrbücher und Tutorials sind hier bewusst ausgeklammert.
Das Nutzungskonzept eines Papier- oder PDF-Dokuments ist uns quasi in die Wiege gelegt. Wir bezeichnen es als ein buchorientiertes Vorgehen mit folgenden typischen Verhaltensweisen:
Fortlaufendes Lesen der Informationen Seite für Seite
Hin- und Herblättern zwischen Seiten für ein überfliegendes Lesen
Orientierung mit Hilfe des buchbezogenen Gefühls "das steht vorne" und "jenes steht weiter hinten" im Dokument; ein Inhaltsverzeichnis am Dokumentanfang und die Überschriften im Dokument verstärken dieses Gefühl
Technische Redaktionen gehen bei dokument- oder buchbezogenen Dokumentationen üblicherweise top-down vor.
Ausgehend von allgemeinen Begriffen werden die produktbegleitenden Informationen nach und nach immer detaillierter. Die technischen Redakteure hoffen, möglichst alle Benutzerfragen indirekt abzudecken.
Die Anwender lesen das Dokument entweder Seite für Seite oder versuchen, top-down die erforderlichen Informationen zu identifizieren. Haben die Anwender eine konkrete Fragestellung, „scannen“ (überfliegendes Identifizieren geeigneter Schlüsselbegriffe) und „skimmen“ (Abschöpfen einer konkreten Detailinformation) sie die Texte.
Ein Inhaltsverzeichnis, Überschriften, Seitennummerierungen, ein Index oder digital über eine sequenzielle Suchfunktion sollen das Skimming und Scanning in dokumentorientierten Anleitungen erleichtern.
Die sequenzielle Suche, also die Suche nach einer eingegebenen Buchstabenfolge, bietet für das frage- oder stichwortorientierte Vorgehen allerdings nur eine schlechte User Experience. Die Anwender können in der sequenziellen Suche keine Wörter kombinieren, um ihre Suche zu konkretisieren. Der ideale Zweck einer technischen Dokumentation ist mit PDF-Dokumenten zumindest auf Smartphones nicht erfüllbar.
Typischerweise nutzen Anwender eine Anleitung erst, wenn sie eine der folgenden oder eine ähnliche Frage haben:
"Was muss ich tun, um …?"
"Wie verwende ich die Funktion …?"
"Was bedeutet die Fehlermeldung …"
"Warum funktioniert … nicht?"
Für diesen kontext- und handlungsbezogenen Informationsbedarf wäre es viel besser, wenn die Anleitung genau die Antworten auf die Anwenderfragen liefern würde. Oft führt ein solcher Frage-Antwort-Ansatz zu FAQ (Frequently Asked Questions). FAQ decken allerdings nur eine kleine und eher willkürliche Teilmenge der Anwenderfragen ab und präsentieren völlig unzusammenhängende Informationsschnipsel.
Neue Nutzungskonzepte für Anleitungsinformationen
Der Frage-Antwort-Ansatz legt ein anderes Dokumentationskonzept nahe. Ein Musterbeispiel für den Frage-Antwort-Ansatz ist das Lexikon mit alphabetischer Reihenfolge, für das Wikipedia als Referenz dienen kann:
Wikipedia Artikel / Topic zum Thema Papierflieger
Im Gegensatz zu einem einfachen Lexikon stellt Wikipedia zu jedem Begriff einen umfassenden Artikel bereit, der verschiedene Gesichtspunkte beleuchtet und nicht nur eine kurze Begriffsdefinition enthält.
Als eine der wenigen Firmen hat Porsche eine überwiegend lexikonartige Gliederung für die Betriebsanleitungen gewählt:
Porsche-Anleitung: Der Hauptteil ist als Lexikon strukturiert
Interessant hierbei: Das Inhaltsverzeichnis gruppiert die alphabetisch gegliederten Informationen in Anwendungsbereiche und repräsentiert so nicht mehr die Seitenreihenfolge im Buch. Damit löst sich Porsche auch in der Papieranleitung von der klassischen Buchstruktur.
Inhaltsverzeichnis der Porsche-Anleitung: Die Darstellung zeigt nicht die Seitenreihenfolge des Dokuments
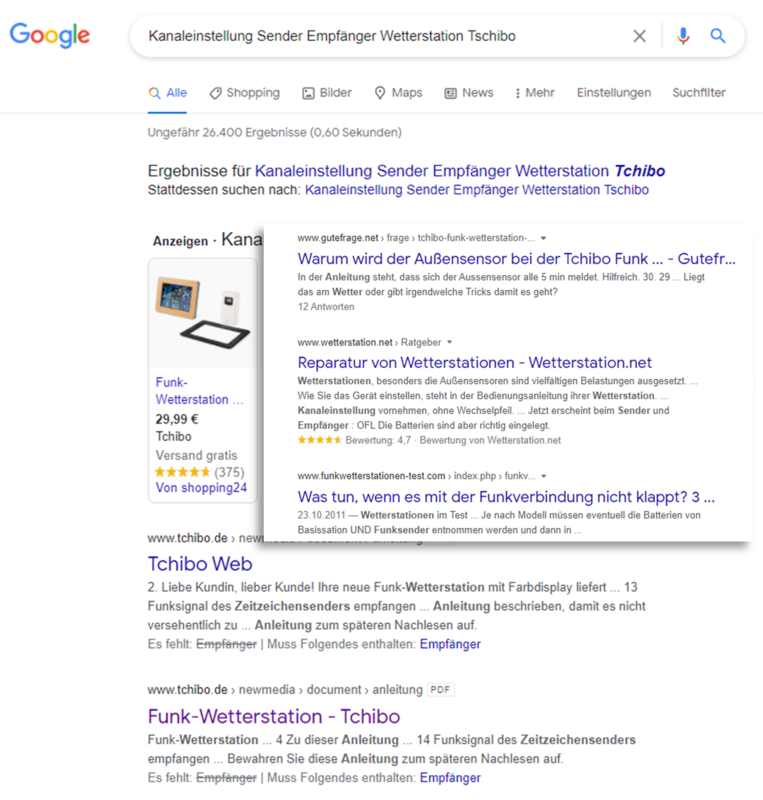
Die Google-Suche geht noch weiter: Zu den eingegebenen Suchbegriffen erzeugt Google zusätzlich zu den allgemeinen Fundstellen "Schnellantworten" in Form von Snippets (Microcontent):
Ergebnis einer Google-Suche. Gegebenenfalls mit dynamisch generierten „Snippets“ z. B. Begriffsdefinitionen
So bietet die Google-Suche vielen Anwendern bereits eine bessere User Experience als eine Papier- oder PDF-Anleitung des Produktherstellers.
Noch wichtiger in der Google-Suche ist die Indexierung von Beiträgen anderer Anwender. Diese Beiträge liefern immer öfter die gewünschten Antworten, da viele Produkthersteller zwar Grundlagen abdecken, aber nur selten spezifischere Problemlösungen beschreiben.
Erst mit dem Blick auf Nutzungskonzepte und Nutzungskontexte wird deutlich, dass ein Technologiewechsel von PDF nach HTML nur die Basis bilden kann für eine neue Denkweise der Dokumentationsnutzung. Bei itl haben wir für diesen neuen Blick den Begriff der "Digitalen Benutzerassistenz" geprägt.
2) Von HTML-Seiten zu benutzerzentrierten Topics
Digitale Benutzerassistenz
Die Basis einer Digitalen Benutzerassistenz bilden Informationsobjekte, die allein oder in einer Zusammenstellung Anwenderfragen gezielt beantworten und auf Endgeräten wie Smartphones oder Gerätebildschirmen geeignet präsentiert werden. Die optimale Informationsaufbereitung wird auch als positive oder optimale Usability bezeichnet. Die Normenreihe ISO 9241 definiert die Digitale Benutzerassistenz im weiteren Sinn als positive User Experience (UX).
HTML-Seiten als typisches Präsentationsmedium für Topics
HTML-Seiten haben eine beliebige Länge und keine Seitenumbrüche.
Längere HTML-Seiten lassen sich vertikal scrollen, was dank Mausrad, Tastatur und Wischgesten nur selten ein Usability-Problem darstellt – im Gegensatz zum horizontalen Scrollen.
Inhalte von HTML-Seiten stehen für sich allein und kennen kein Vorher und Nachher.
Mit diesen Eigenschaften sind HTML-Seiten geeignet für in sich abgeschlossene Frage-Antwort-Konzepte und für Topic-orientierte Informationen.
Typische Nutzungslogik von HTML-Seiten
Das Suchen und Finden von Informationen in einem elektronischen Informationssystem ist das, was wir heute gern als "Googeln" bezeichnen. Wir stellen eine gezielte Frage oder nennen einen Begriff, zu dem wir eine Definition benötigen. Eine solche Volltextsuche ist auf HTML-Seiten gut geeignet, lässt sich über den redaktionellen Index einer Papierdokumentation aber nur sehr schwerfällig nachahmen. Nur eine lexikalische Gliederung folgt am ehesten dem Prinzip des "Googelns", aber wer nutzt noch gedruckte Lexika?
Wenn wir die Informationen nun buchorientiert redaktionell top-down planen, machen wir uns keine Gedanken darüber, ob eine Seite eine bestimmte Anwenderfrage beantwortet. Wir hoffen, alle Seiten würden alle Anwenderfragen abdecken.
Bei einer bewussten Planung von HTML-Seiten (Topics) müssen wir uns also darüber klar werden, welche Frage das Topic beantworten soll. Die Anwender sollen nicht von Seite zu Seite springen oder sich die Antworten aus der Navigationsstruktur ableiten müssen.
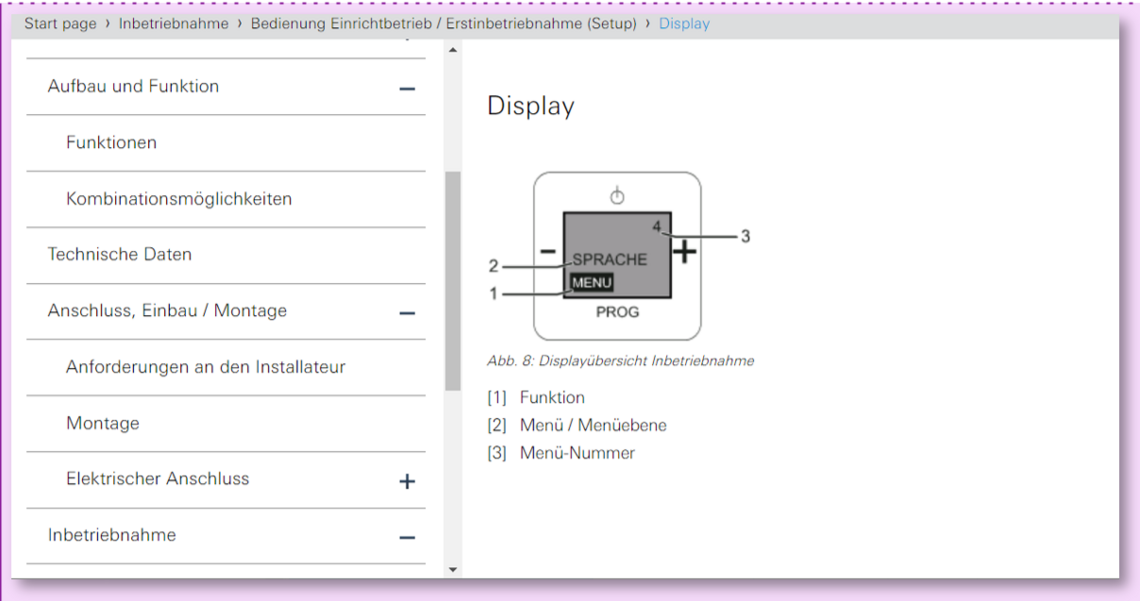
Wenn die Buch- in die Topic-Logik umgewandelt wird, enstehen oft nicht optimale Topic-Inhalte wie im folgenden Bild:
Beispiel einer HTML-Konvertierung aus einer ursprünglichen PDF-Dokumentation
Die Anwender erfahren zwar ein paar Bezeichnungen zum Produkt, aber erst im Zusammenhang mit weiteren Informationen ist ein für den Anwender sinnvolles Informationsziel erreicht. Das Problem des Nutzungskontextes fällt in Papier- oder PDF-Dokumenten überhaupt nicht auf, weil die weiterführende Information ggf. auf derselben Seite steht. Das automatische Aufsplitten von Dokumenten auf einer bestimmten Überschriftenebene in separate HTML-Seiten erzeugt zum Teil wenig brauchbare Topics.
Bottom-up-Planung für Inhalte von HTML-Topics
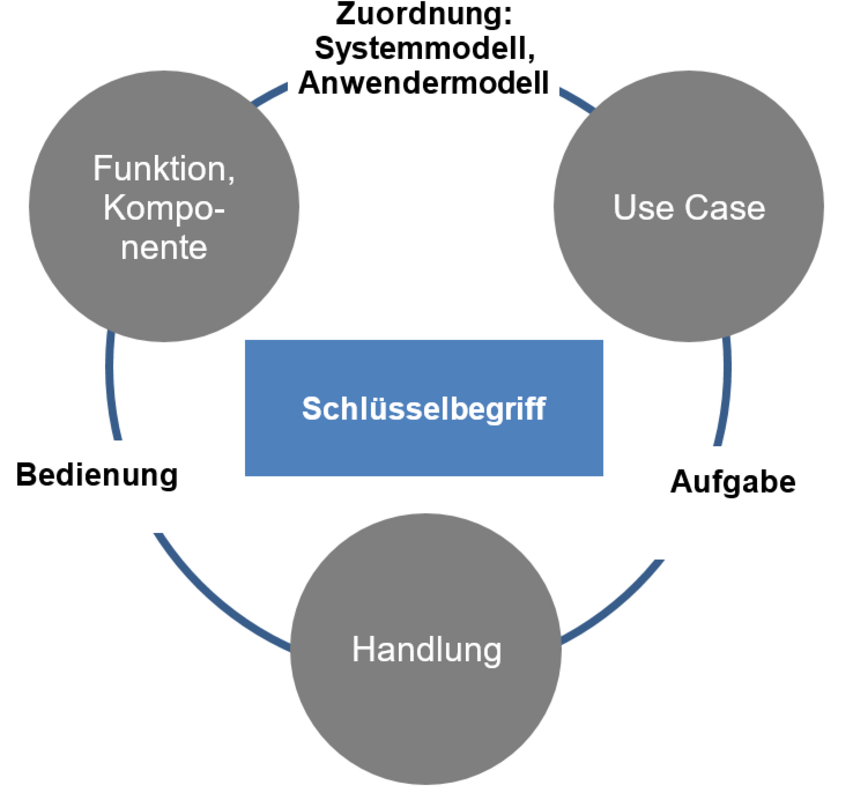
Für eine optimale Topic-Orientierung planen wir bei itl den Inhalt bottom-up. Ausgehend von den Schlüsselbegriffen der darzustellenden Information, prüfen wir, wie die Schlüsselbegriffe den drei typischen Sichtweisen auf ein Produkt zuzuordnen sind:
Produkt (Funktion, Komponente)
Aufgaben (Use Cases)
Handlung (Produkt bedienen)
Im zuvor gezeigten Beispiel ist das Produkt jeweils die Bezeichnung des Bedienelements, der Use Case die Funktion, in der das Bedienelement benutzt wird und die Handlung die Bedienlogik (Drücken, Wischen, Klicken, Reihenfolge der Bedienung, …).
Aus den gedanklichen Zuordnungen ergeben sich die einzelnen Fragestellungen und als Antworten die einzelnen Topics. Die Bedienelemente (oder auch die Funktionen) können unterschiedlich verwendet werden, wodurch sich zahlreiche Topics ergeben.
Aussicht
Topics können trotz der einfachen Struktur aus Überschrift und Inhalt unterschiedlich gestaltet sein. Zahlreiche Diskussionen ranken sich um die Frage, ob kurze Frage-Antwort-Darstellungen nicht ein zu stark fragmentiertes System darstellen, das eine konzeptuelle Informationsverarbeitung und echtes Verstehen verhindert. Das gilt insbesondere für die semantisch strikt getrennte Topic-Typisierung nach DITA.
Seien Sie gespannt auf meinen nächsten Blogbeitrag!
Hallo Dietrich, sehr gerne können wir das in deinem Dienstag-Meeting vertiefen. Hier noch ein paar weitere Schlüsselbegriffe, die in den nächsten Beiträgen folgen sollen:
- Topic-Typen, Super-Topics
- Topic-Cluster, microDocs
- Liquid-PDF statt HTML-Konvertierung
- User Experience Design für topic-orientierte Informationen
Gerne würde ich auch zu jedem Schlüsselbegriff immer ein Bild zeigen dürfen, bei einer gemeinsamen "Bildbetrachtung" merkt man noch besser, ob man die gleichen Bilder zum Thema im Kopf hat.
Juhl Dietrich
[14. Februar 2021]
Hallo Dieter,
dein Beitrag gefällt mir sehr gut. Ich würde gerne das ein oder andere auch noch diskutieren und vertiefen wollen. Vielleicht können wir das mal in meinem Dienstagstreffen machen.
Dieter Gust war von 1986 bis 2022 bei itl. Er legte seinen Schwerpunkt auf die Themen Prozessautomatisierung, kontrollierte Sprache und nutzungsgerechte Aufbereitung von Dokumentation. Seit Mai 2020 ist Dieter Gust TÜV-zertifizierter Professional Scrum Master und Product Owner.
Der Blog-Artikel meines Kollegen Dieter Gust beginnt mit einer Anekdote zum Thema Buchdruck – und das aus guten(berg‘schen) Grund. Ein grobes Fazit im Bereich der Technischen Dokumentation mag sein, dass die Technik des Buchdrucks noch heute relevant ist, auch wenn wir immer weiter digitalisieren.
Gibt es auf Grund der neuen dynamischen Möglichkeiten einer App auch neue Erkenntnisse, die ganz andere Herangehensweisen bei der Nutzung elektronischer Dokumentation nahelegen? Und welche Funktion kann ein Anwender intuitiv sofort nachvollziehen, ohne große Erklärungen? Zwei Beispiele können die „neuen“ Herausforderungen verdeutlichen.
Die ersten beiden Teile der Blogbeitragsreihe haben die rechtlichen Grundlagen und allgemeinen Anforderungen an barrierefreie Inhalte behandelt. Es gibt eine Vielzahl an bestehenden Richtlinien und Normen, die bei der Erstellung barrierefreier Inhalte genutzt werden können und sollten. So liefern z. B. die WCAG (Web Content Accessibility Guidelines) klare Vorgaben für die Umsetzung.
Wir nutzen Cookies auf unserer Website. Einige von ihnen sind technisch notwendig, während andere uns helfen, diese Website zu verbessern oder zusätzliche Funktionalitäten zur Verfügung zu stellen.








Kommentar schreiben